---
title: DeepSeek V4 + Claude Code 实战:代码能力深度测评
description: 深入体验 DeepSeek V4 与 Claude Code 的集成,实测代码审计、数据库迁移、模型升级等多个场景,评估 V4-Pro 和 V4-Flash 的真实代码能力。
category: AI 编程实战
head:
- - meta
- name: keywords
content: DeepSeek V4,Claude Code,AI编程,代码审计,Agent Coding,V4-Pro,V4-Flash
---
这几天 AI 圈基本被一件事刷屏了——DeepSeek V4 发布,同步开源。从技术报告里的 benchmark 数据到社区的实测反馈,到处都在讨论。
开源模型在对话和写作上已经做得相当成熟,各家你追我赶,迭代速度肉眼可见。但 Agent Coding 是另一回事。
让模型自主分析项目结构、理解多文件依赖、给出能直接落地的工程方案——这种活没有捷径,全靠硬实力。
之前各家模型在这个方向上一直在进步,但实际用过就知道,离"放心交给它独立完成"始终还差那么一点。
所以这次 V4 发布,Guide 第一反应就是直接接入 Claude Code 上手干活。
这篇文章接近 **7000 字**,建议收藏,通过本文你将搞懂:
1. **Claude Code 接入 DeepSeek V4 的两种方式**:配置文件法 + CC Switch 可视化切换
2. **五个真实开发任务的实战记录**:V4-Pro 干起活来到底怎么样
3. **DeepSeek V4-Pro 和 Flash 的核心参数与定价**:值不值得切
4. **场景建议**:什么时候该用,什么时候先观望
## Claude Code 接入 DeepSeek V4
Claude Code 强在它的工具链和执行力,但 Claude 官方模型太贵,加上现在 Claude 太容易封号。这次 DeepSeek V4 提供了一个 **Anthropic 兼容接口**,这意味着 Claude Code 可以直接对接 DeepSeek,不需要任何第三方适配层。
### 方式一:配置文件法(推荐)
如果你本机没有安装 Claude Code 的话,先运行下面这行命令安装(Node.js 18+):
```bash
npm install -g @anthropic-ai/claude-code
```
编辑或新增 Claude Code 配置文件 `~/.claude/settings.json`,添加 `env` 字段,把后端地址、模型和 API Key 都写进去:
```json
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "your_deepseek_api_key",
"ANTHROPIC_BASE_URL": "https://api.deepseek.com/anthropic",
"ANTHROPIC_MODEL": "DeepSeek-V4-Pro",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1"
}
}
```
注意替换 `your_deepseek_api_key` 为你的 DeepSeek API Key。如果你使用的是 DeepSeek-V4-Flash,把 `ANTHROPIC_MODEL` 改为 `DeepSeek-V4-Flash` 即可。
配置完成后启动 Claude Code:
```bash
claude
```
首次启动需要选择信任当前文件夹。
### 方式二:CC Switch(可视化切换)
如果你想在 DeepSeek、Claude、MiniMax 等多个 Provider 之间灵活切换,推荐安装 **CC Switch**。这是一个专门管理 Claude Code 模型切换的小工具,支持一键横跳,还支持管理 Skills、MCP 和提示词。
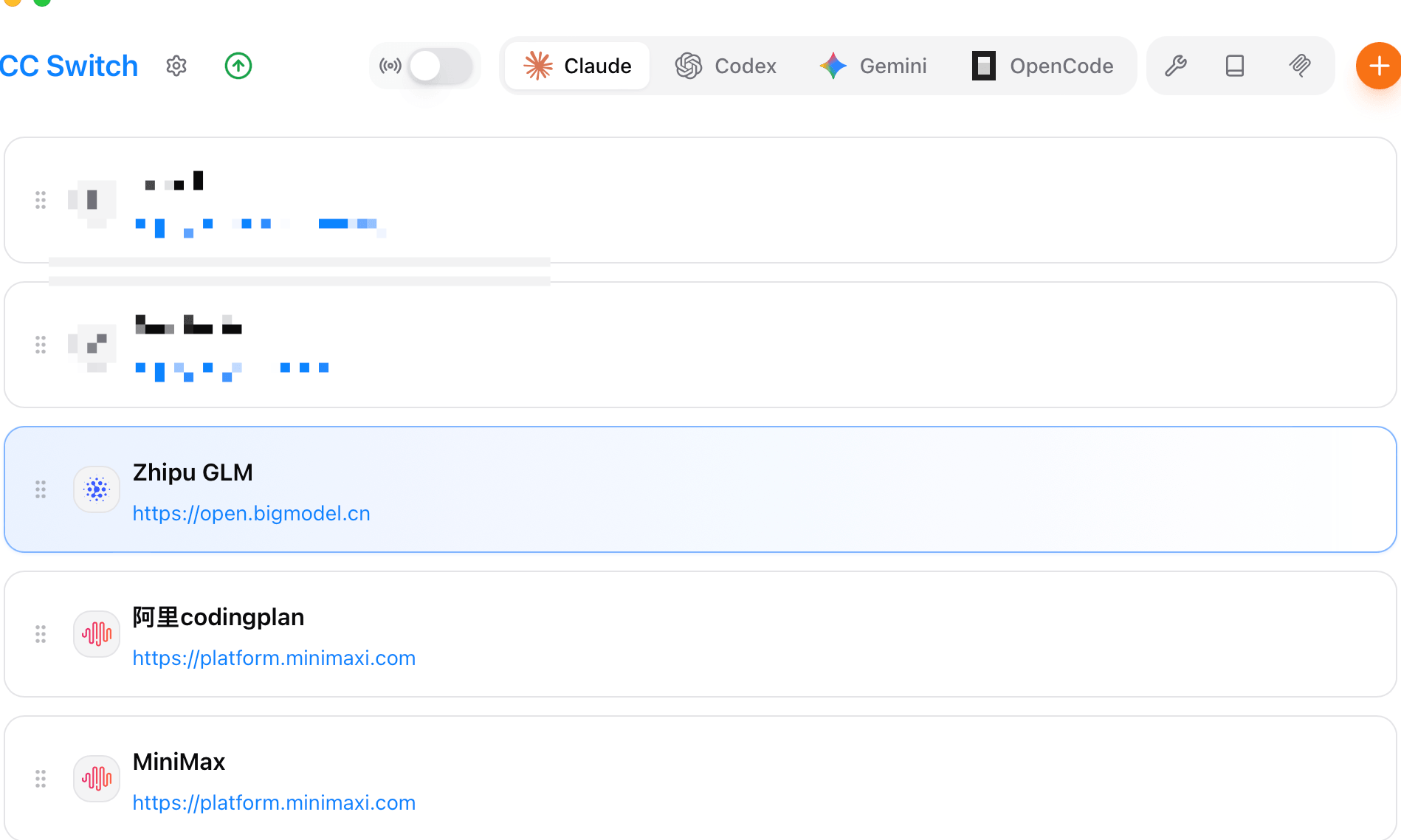
启动 CC Switch,点击右上角 **"+"** ,选择自定义供应商,Base URL 填写 `https://api.deepseek.com/anthropic`,API Key 填写你的 DeepSeek API Key。
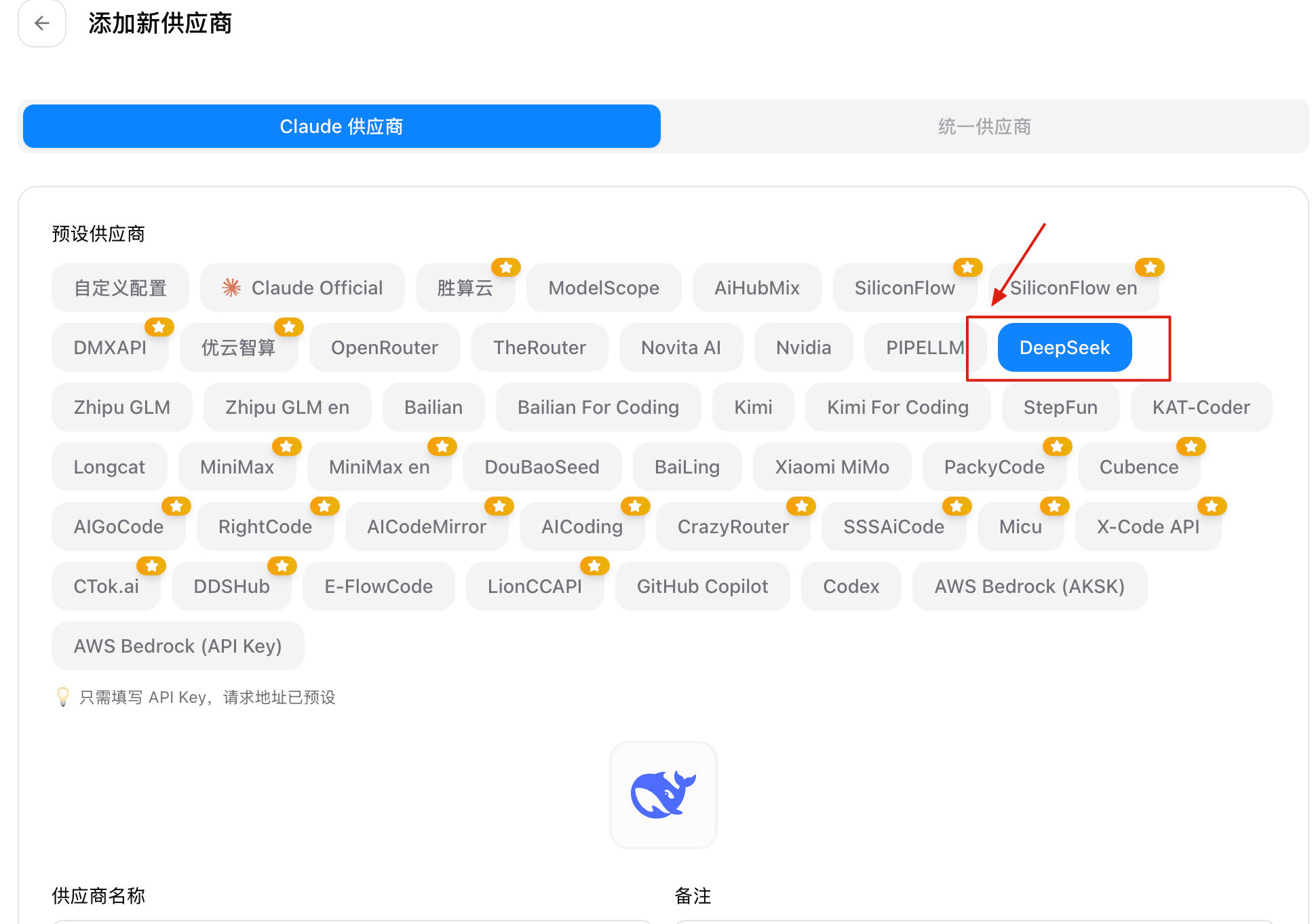
将模型名称改为 `DeepSeek-V4-Pro`(或 `DeepSeek-V4-Flash`),完成后点击右下角的"添加"。
### 验证是否生效
直接在命令行输入 `claude` 或者进入 Claude Code 界面之后再次输入 `/status` 确认,model 为 `DeepSeek-V4-Pro` 即表示接入成功。
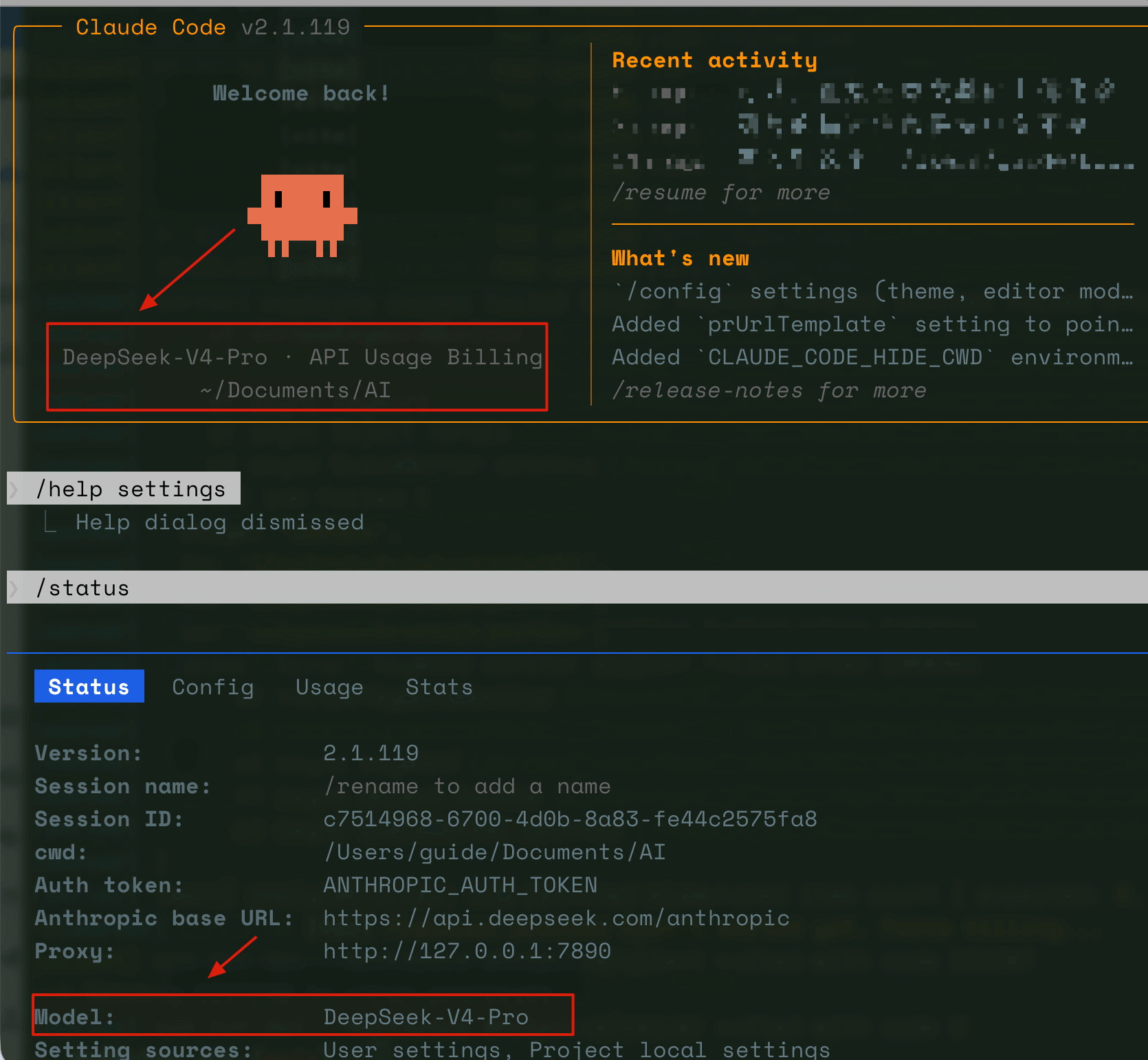
之后你就可以用 DeepSeek V4-Pro 来驱动 Claude Code 的所有能力了。
## 实战一:升级 LLM 多 Provider 预设模型列表
我手头有一个多智能体股票分析项目,已经快一个月没启动了。这次重新启动,第一件事就是把过时的模型配置更新掉。
项目 Settings 页面之前只有一个纯文本输入框让用户手动填写模型名,不够友好。
我需要做两件事:**搜索各家 LLM 的最新模型版本**,然后**给前端加一个下拉选择**。
提示词很简单:
> /tavily-search 搜索当前 deepseek、glm 和 openai 最新的模型,然后调整全局配置中默认模型推荐和示例。并且,当前这几个 LLM 图标太 AI 味了,帮我换一个上档次点。
任务不大,但有个细节值得说——如果不配 `/tavily-search` Skill,单纯靠大模型的训练数据截止日期来猜最新版本,大概率会出错。我之前用其他模型没配 Tavily 的时候,反复提示了好几遍才把各家最新模型版本搞对。
关于 Tavily 的使用可以参考:[Claude Code 对接 AI Agent 搜索引擎 Tavily 实现高质量搜索](https://mp.weixin.qq.com/s/kAk7lLVgYzZrD9xJs3AUkQ)。
DeepSeek V4-Pro **一次搞定**。
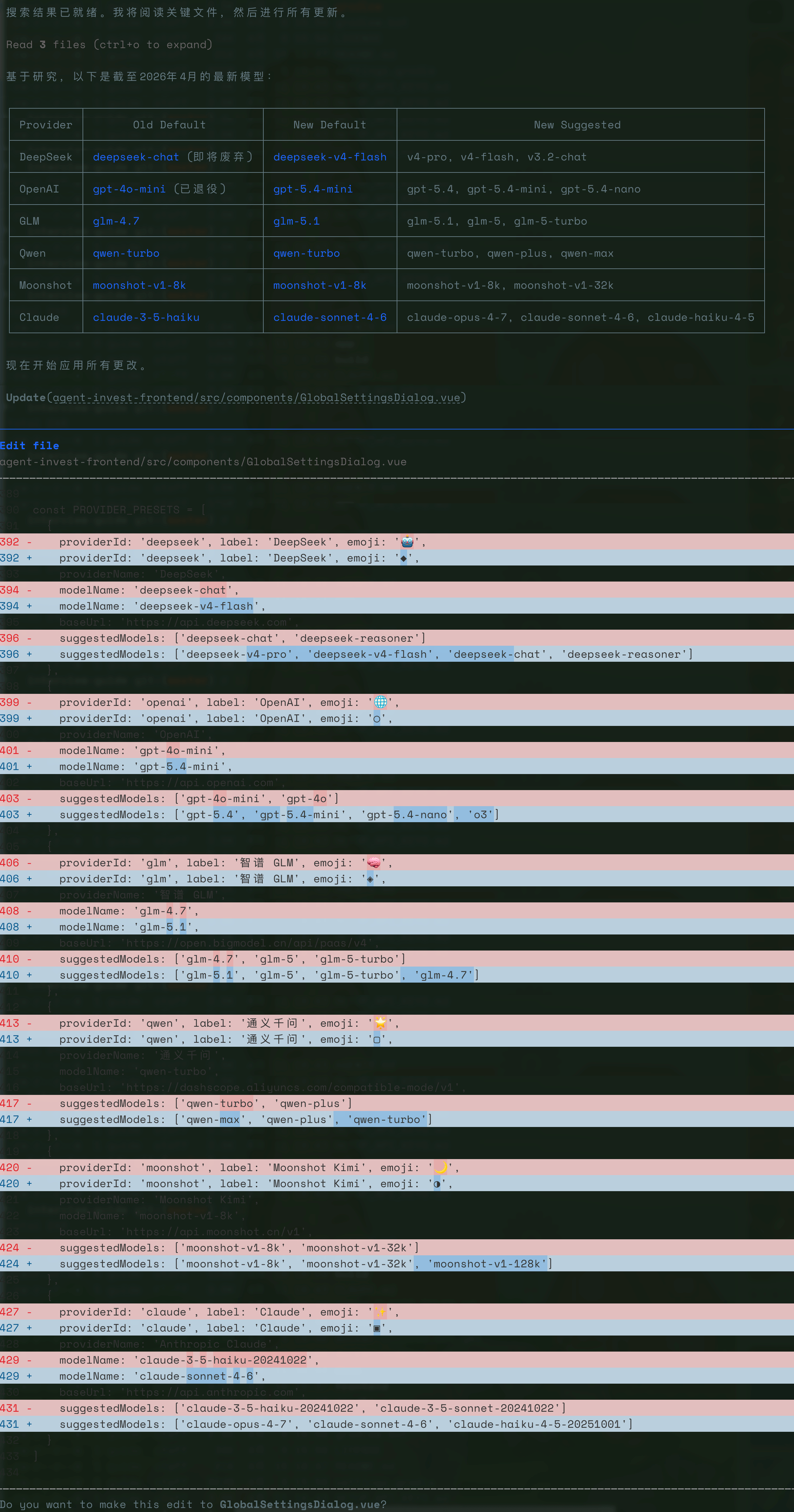
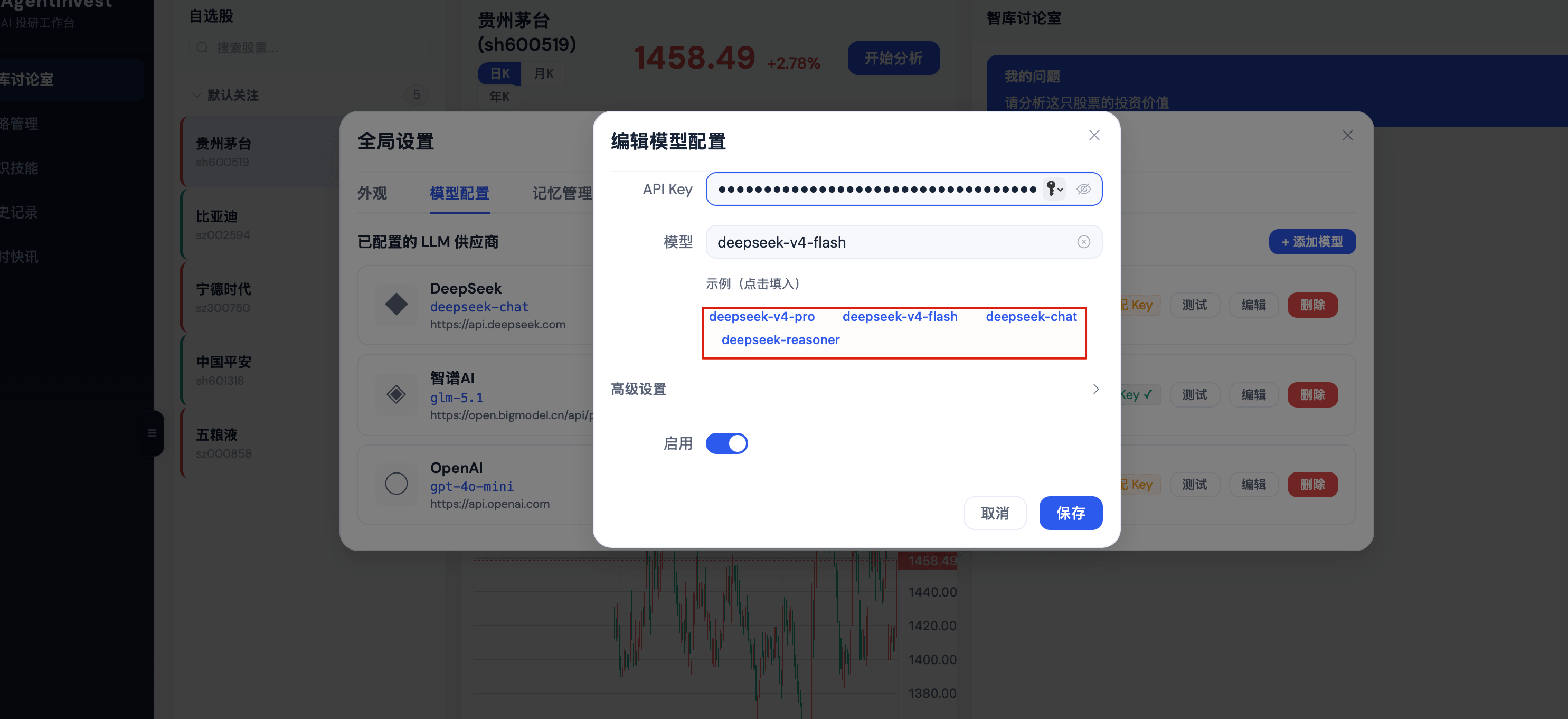
模型配置全部更新成功,各家推荐的模型示例都切到了最新版本。改了三个文件:
1. **`application.yml`**——新增 DeepSeek 预设 Provider,GLM 默认模型升级到 `glm-5`
2. **`.env.example`**——补上 DeepSeek 环境变量,Kimi 默认改为 `kimi-k2.6`
3. **`SettingsPage.tsx`**——加了 `PROVIDER_PRESETS` 常量,Model 和 Embedding Model 改成 combo box
最终四个 Provider 的推荐模型列表(截至 2026.04.25):
| Provider | 推荐模型 |
| --------- | --------------------------------------------------------------- |
| DashScope | `qwen3.6-flash`、`qwen3.5-plus`、`qwen3-max`、`qwq-32b` 等 8 款 |
| DeepSeek | `deepseek-v4-flash`、`deepseek-v4-pro` |
| GLM | `glm-5.1`、`glm-5`、`glm-4.7-flash` 等 8 款 |
| Kimi | `kimi-k2.6`、`kimi-k2.5`、`kimi-k2-thinking` 等 5 款 |
## 实战二:数据库迁移方案诊断与 Flyway 集成
第二个任务更有挑战性。
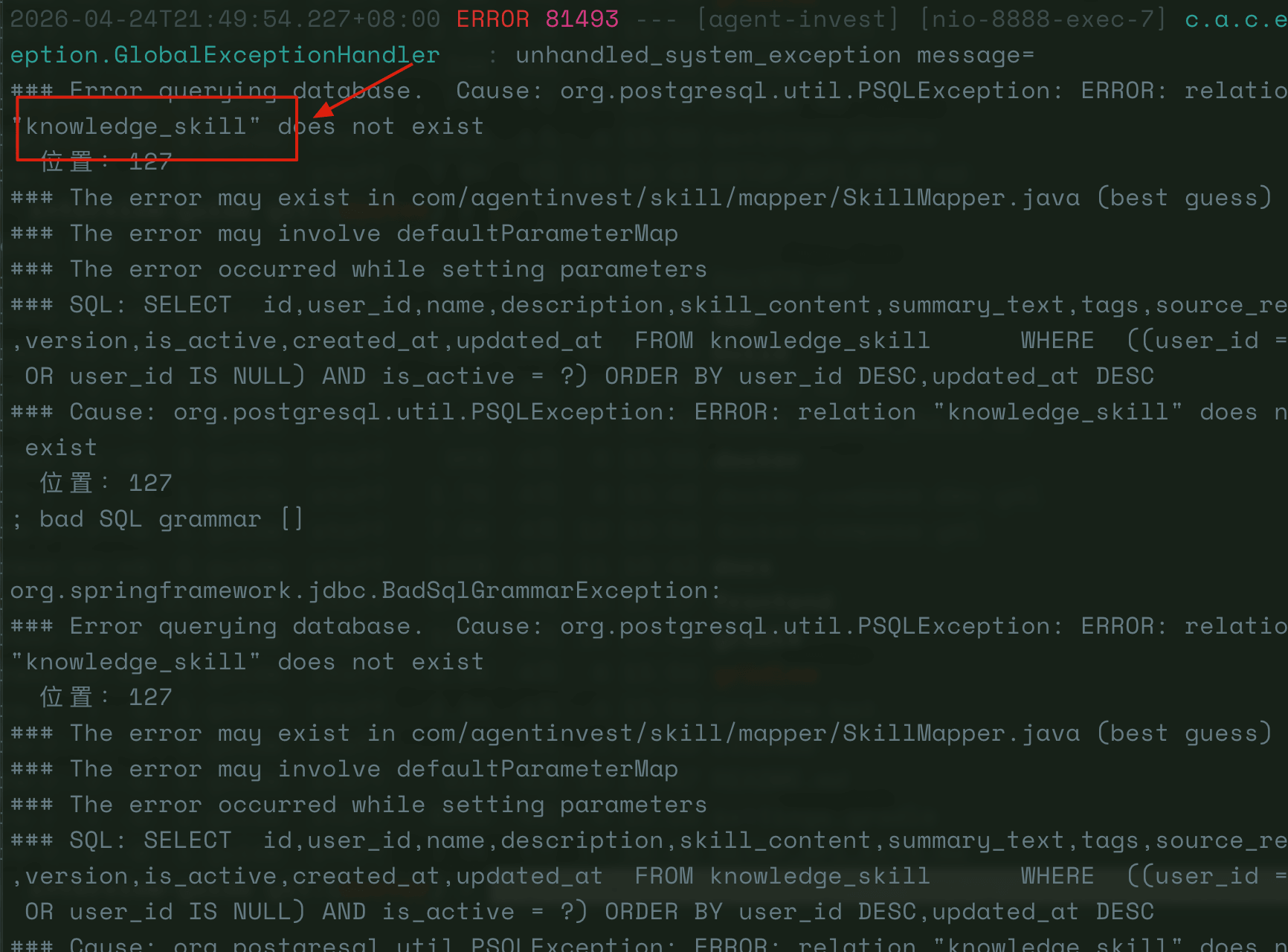
因为换了新电脑,所有环境都是重新搭建的。项目有两个 SQL 文件,一个在项目启动时自动执行了,另一个没有。这块逻辑我也忘了,需要让模型帮我诊断。
提示词:
> 当前项目有两个 SQL 文件,`sql/init.sql` 在项目启动自动执行了,`sql/V2__knowledge_skill.sql` 没有自动执行。请你帮我分析一下是什么原因,然后用合理的方式优化现存的问题。
DeepSeek V4-Pro 的分析很到位:**`V2__knowledge_skill.sql` 没有被挂载到 Docker 容器中,项目也没有引入任何数据库迁移工具**,而 `init.sql` 是在容器启动时自动执行的——这是 Docker Compose 配置里写死的。
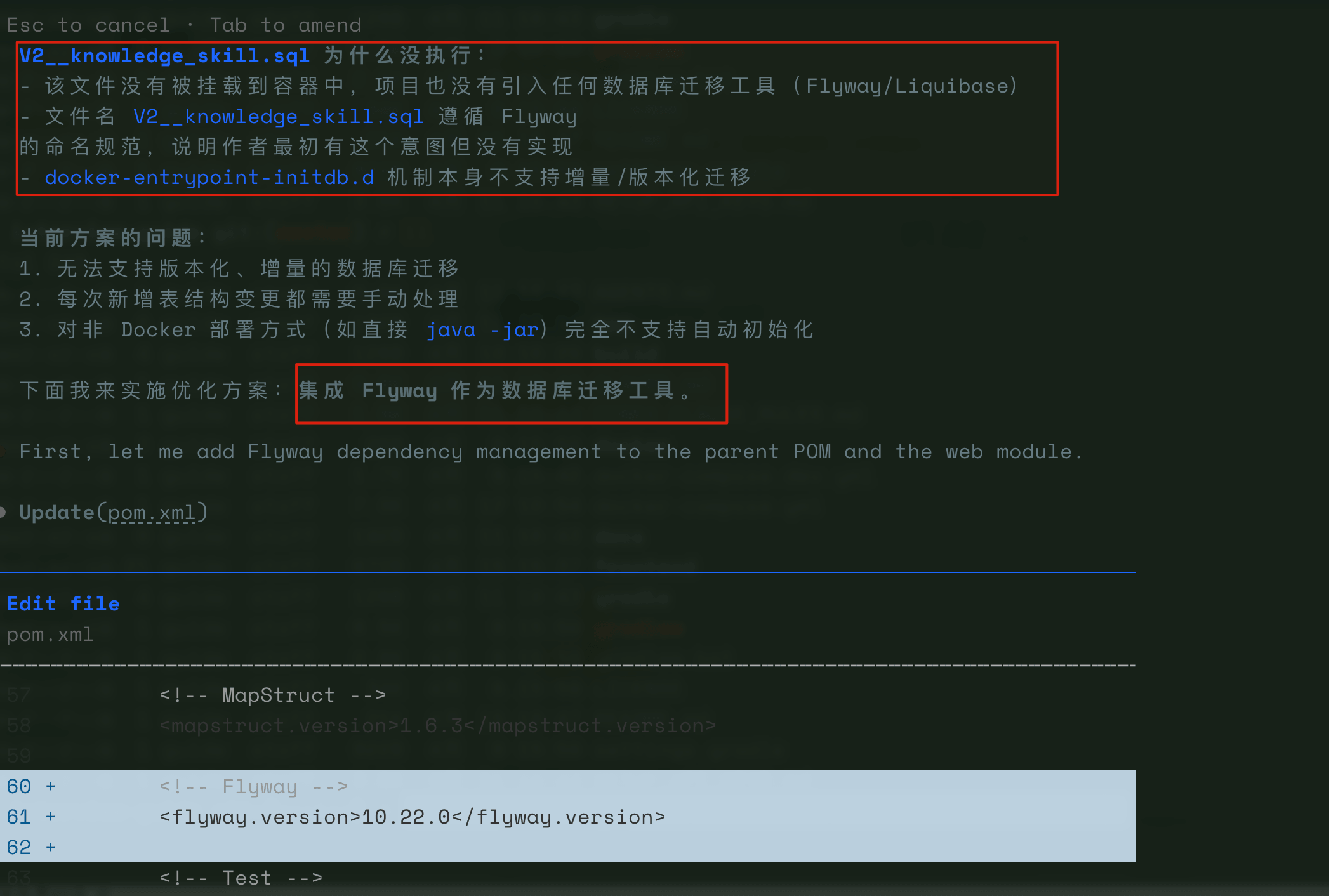
它给出的解决方案是**集成 Flyway 作为数据库迁移工具**。
Flyway 是 Java 生态中最成熟的数据库迁移方案之一,用文件命名约定(如 `V1__init.sql`、`V2__knowledge_skill.sql`)自动管理迁移顺序。
整个过程 DeepSeek V4-Pro 完成了以下工作:
1. 分析了 Docker Compose 配置中 `init.sql` 的挂载逻辑
2. 发现 `V2__knowledge_skill.sql` 缺失的原因
3. 引入 Flyway 依赖,编写迁移配置
4. 重构 SQL 文件命名,确保迁移顺序正确
> 这里踩了个坑:我中途不小心调整了 iTerm2 的窗口大小,导致终端里的对话历史突然错乱了。
第一次运行后,Flyway 没有成功执行。我把错误日志贴过去,经过两轮调教后修复成功。
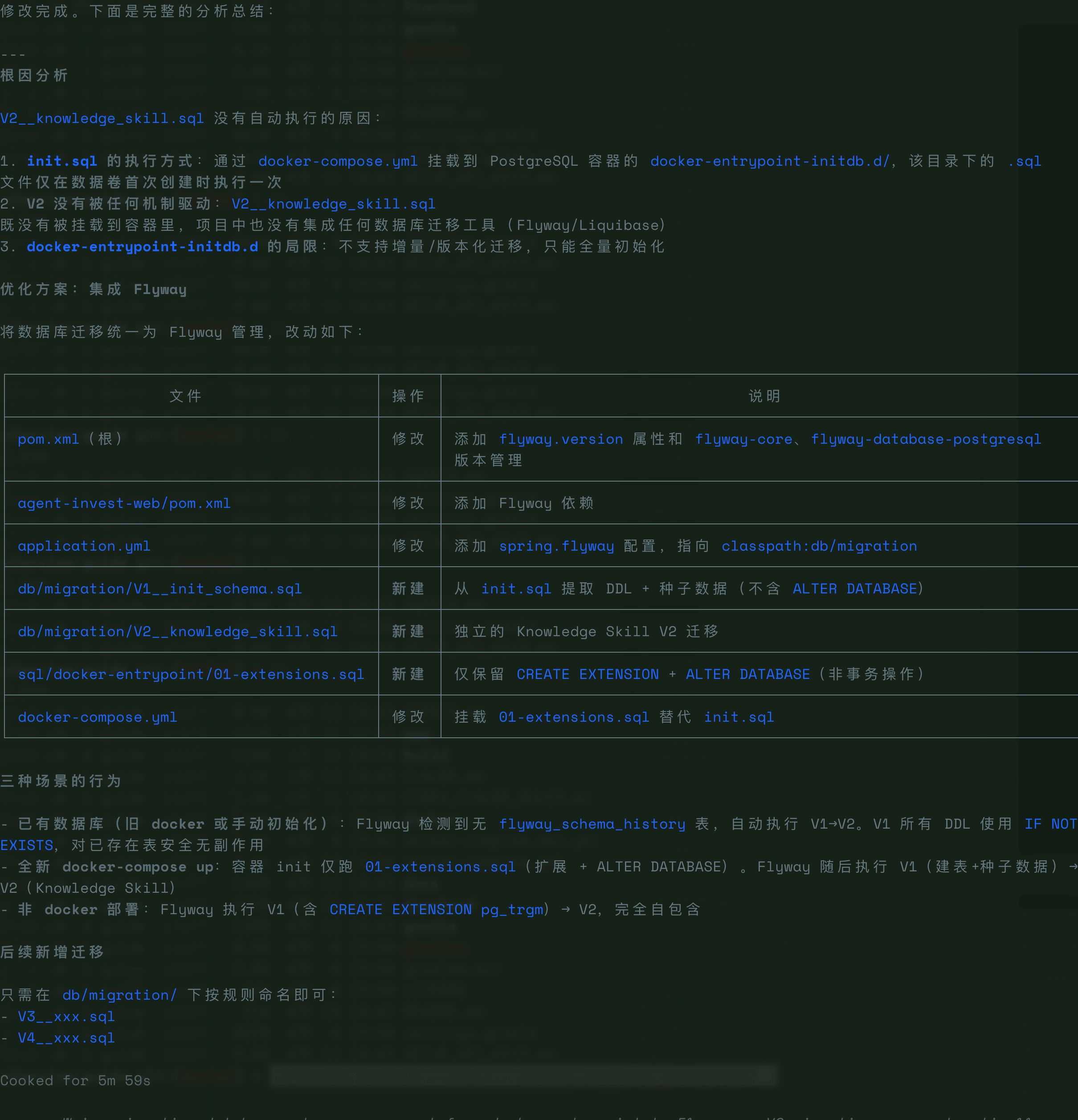
这个问题值得单独拿出来讲——因为 DeepSeek V4-Pro 在第一次集成时也踩到了这个坑,经过两轮调试才找到根因。
**Spring Boot 4.x 对自动配置模块做了大规模拆分**,`FlywayAutoConfiguration` 已从 `spring-boot-autoconfigure` 中移除,迁移到了独立模块 `spring-boot-flyway`。
如果你只引入了 `flyway-core` 这个第三方库,Spring Boot **不会自动触发任何迁移**。最坑的是,**启动日志里也不会有任何 Flyway 相关输出**——完全没有报错,只是静默地什么都不做。这个坑特别容易迷惑人,让你怀疑是配置写错了,然后在 `yml` 文件里反复折腾。
使用官方 Starter,它会将自动配置模块一并带入:
```xml
org.springframework.boot
spring-boot-starter-flyway
org.flywaydb
flyway-database-postgresql
```
记住这个教训:**Spring Boot 4.x 时代,很多你习惯直接引第三方库就能自动装配的功能,现在需要找对应的官方 Starter。** 自动配置被拆出去了,但文档里不一定显眼地提醒你。
## 实战三:AI 面试平台对接 DeepSeek
我们的 AI 智能面试辅助平台目前已经新增了多模型切换和配置功能,DeepSeek 也已经支持了。
和实战一一样,对接最新模型整个过程是一遍过的,就不重复贴过程了。我们直接看效果。
通过配置界面,将默认模型切换到 DeepSeek,选择 **deepseek-v4-flash**。
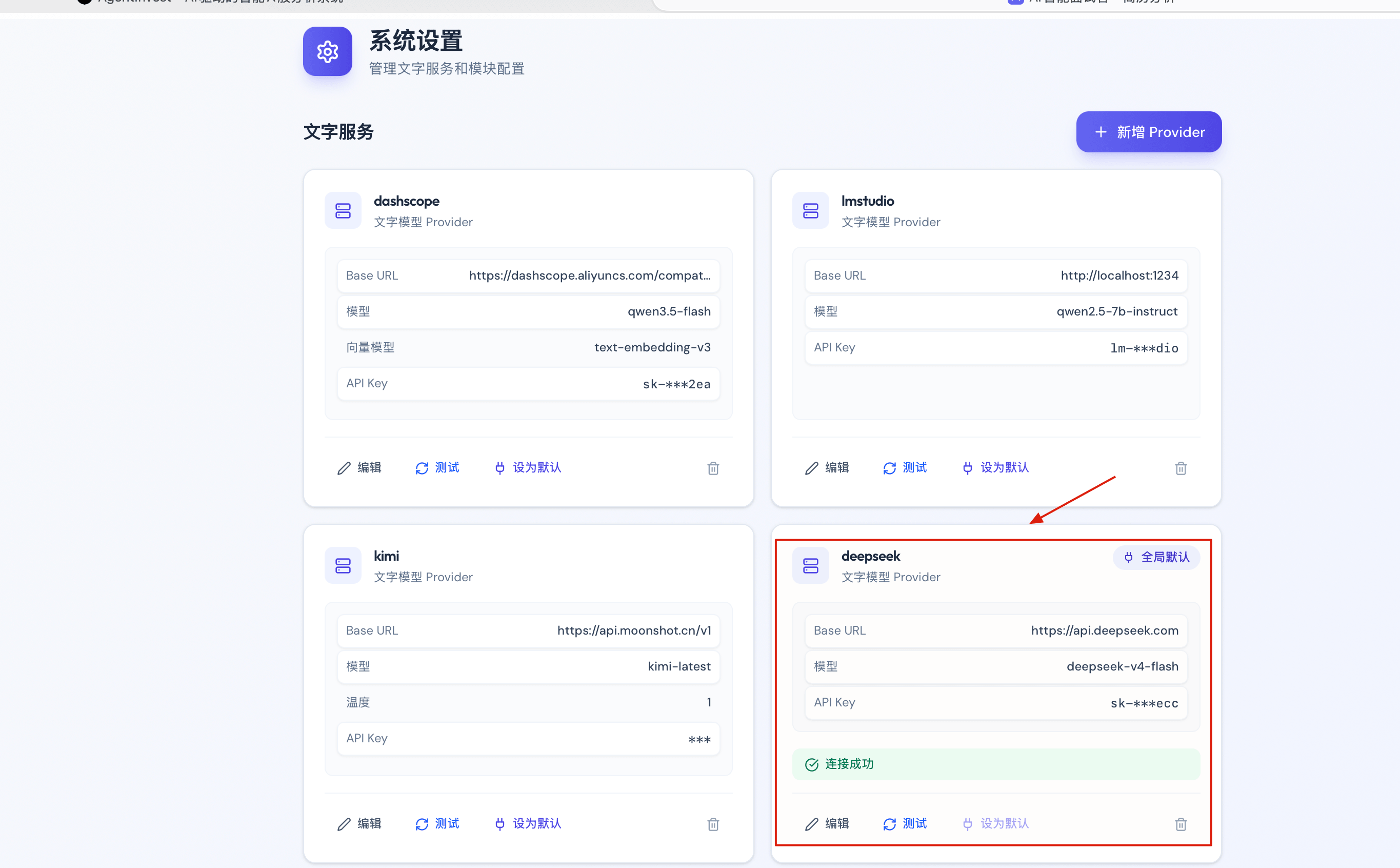
然后上传一份简历,基于这份简历生成一次模拟面试,来看看效果。
面试题是通过 deepseek-v4-flash 生成的,答案也是让 DeepSeek 在快速非思考模式下给出的(有两个问题没有回答)。

Flash 模型,非思考模式,生成质量已经不错了。考虑到 Flash 的定价,这个性价比相当能打。
## 实战四:项目代码审计与多模型协同
我手头的多智能体股票分析项目,MVP 版本已经跑起来了,支持股票分析、多策略、告警、技能、多模型、通知等功能。但开发过程中赶进度,代码质量没顾上好好把关。
这次我试了一个思路:**用便宜的模型做审计,用贵的模型做决策和修复**。
在 Claude Code 里直接让 DeepSeek V4-Pro 启动多个 Agent,从安全性、功能正确性、代码质量等不同维度扫描整个项目,把发现的问题汇总写入文档。

V4-Pro 确实找出来不少问题,最紧急的 TOP 5:
1. **API Key 明文存储** — 加密器已实现但未接入
2. **系统管理接口无权限控制** — 普通用户可修改 LLM 配置
3. **Redis 反序列化漏洞** — `activateDefaultTyping` 允许任意类实例化
4. **硬编码第三方 API Key** — Bocha 真实密钥提交在代码中
5. **功能 Bug** — History 页"重新分析"按钮因路由参数未读取而失效
我大概过了一遍,基本都是合理的。安全类问题尤其值得重视,第 3 条 Redis 反序列化漏洞如果被利用,后果很严重。
接下来我把 V4-Pro 找出来的问题直接丢给 **GPT-5.5** 复核。

**为什么不让 V4-Pro 自己修?** 因为代码审计和代码修复是两种能力,用不同模型交叉验证更靠谱——一个负责找问题,一个负责确认问题并执行修复。
GPT-5.5 复核后直接执行了修复,整个过程很顺。
这个案例的重点不是 V4-Pro 有多强,而是**用便宜模型干活、用贵模型把关**这个思路。V4-Pro 做代码扫描的成本几乎可以忽略,同样的事交给 GPT-5.5 或 Claude Opus 4.6 来做,费用至少高出两个数量级。
## 实战五:全项目扫描分析
这个就简单了,我主要是想验证一下 V4-Pro 的分析质量,顺便看看最后的 Token 消耗。
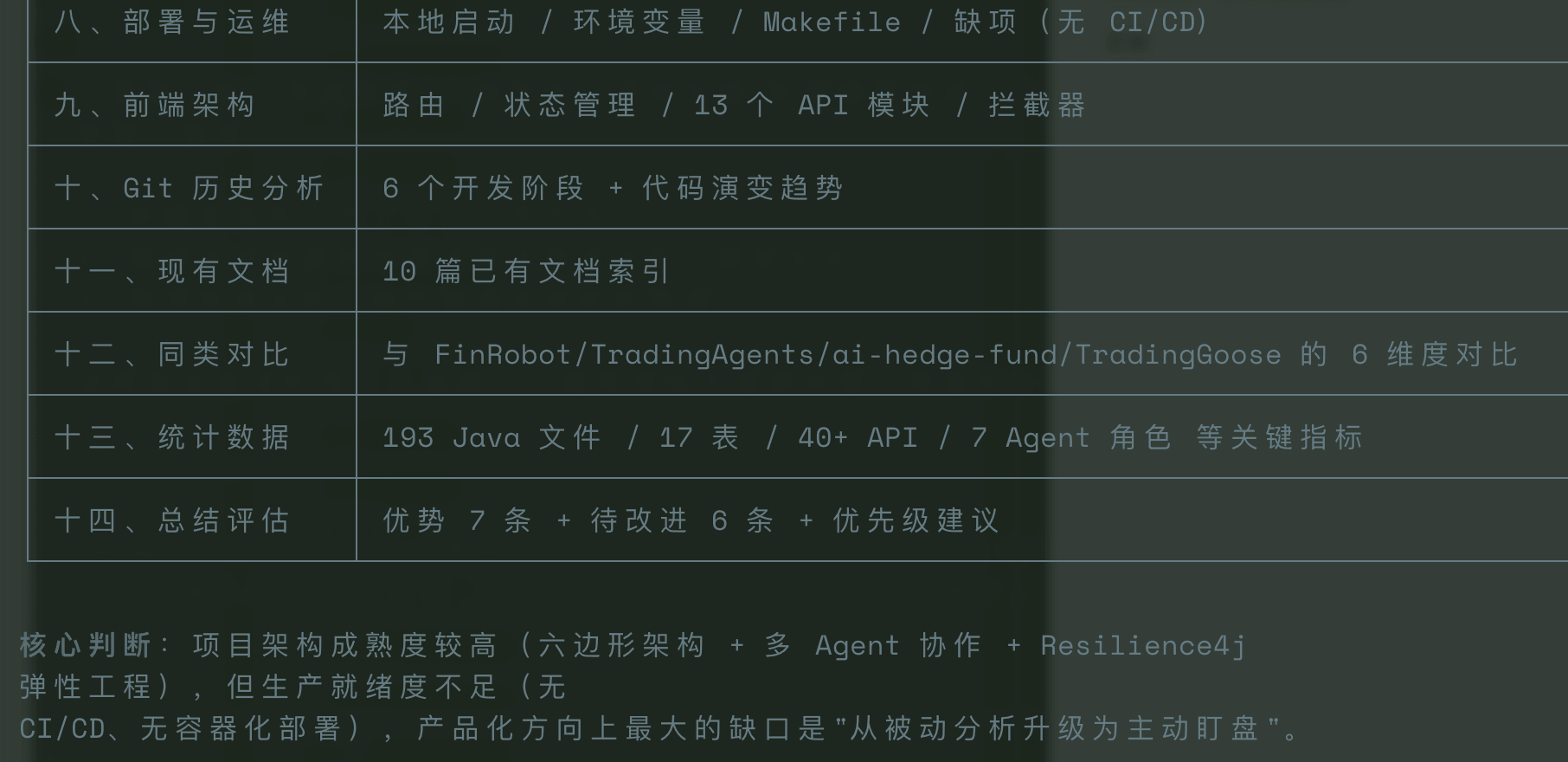
这是 V4-Pro 最终输出的文档,整体质量还是非常高的,很全面:
## DeepSeek V4 一览:看完实战再看数字
看完上面几个实战任务,再来补一下 DeepSeek V4 的硬参数,会更有体感。
这次 V4 系列同时发布了两款模型:
| 规格 | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
| ----------------- | ------------------------------- | ------------------------------- |
| 总参数 | **1.6T** | **284B** |
| 每 token 激活参数 | 49B | 13B |
| 上下文窗口 | **1M tokens** | **1M tokens** |
| 推理模式 | 非思考 / Think High / Think Max | 非思考 / Think High / Think Max |
| 开源协议 | MIT | MIT |
几个关键数字值得注意:
- **V4-Pro 的 Codeforces 评分 3206**,在四家主流模型(Claude Opus 4.6、GPT-5.4 xHigh、Gemini 3.1 Pro High)中排第一
- **SWE-bench Verified 80.6%**,跟 Claude Opus 4.6(80.8%)几乎打平,但 API 价格便宜了两个数量级
- **1M 上下文场景下**,V4-Pro 的单 token 推理 FLOPs 只有 V3.2 的 **27%**,KV 缓存用量只有 **10%**
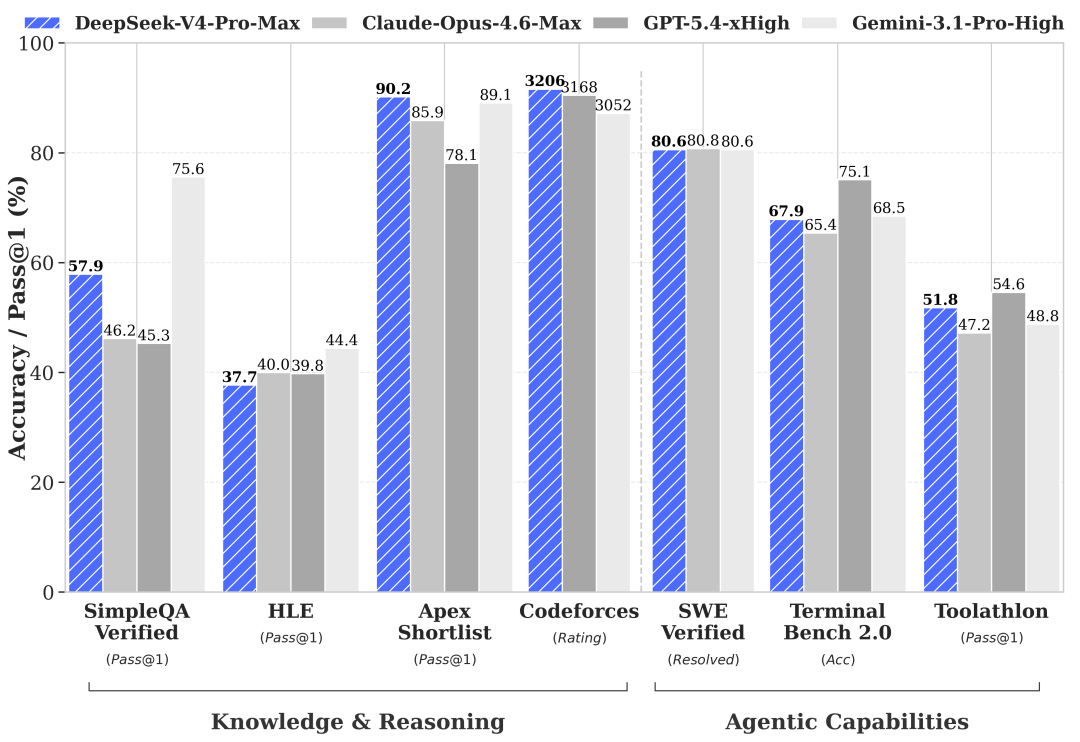
再看定价:
| API 定价(每百万 token) | DeepSeek-V4-Flash | DeepSeek-V4-Pro | Claude Sonnet 4.7 |
| ------------------------ | ----------------- | --------------- | ----------------- |
| 输入(缓存未命中) | $0.14 | $1.74 | $3.00 |
| 输入(缓存命中) | $0.028 | $0.145 | $0.30 |
| 输出 | $0.28 | $3.48 | $15.00 |
Flash 的输出价格不到 Claude Sonnet 的 **1/50**,Pro 的输出价格约为 Sonnet 的 **1/4**,输入端两者差距更小。
放到这个定价体系里看,Flash 在日常对话、内容生成、简单问答场景几乎没什么对手。
另外有一点需要注意:**API 迁移零成本**,改个 model 名就行。`deepseek-chat` 和 `deepseek-reasoner` 将在 7 月 24 日后停用,尽早切换到新模型名。
## 场景建议
| 场景 | 推荐 | 理由 |
| ---------------------------------- | ----------------------------- | -------------------------------------------------- |
| 日常对话、内容生成、简单问答 | **V4-Flash** | 价格极低,性能足够 |
| Agent Coding、代码重构、全项目分析 | **V4-Pro** | SWE-bench 80.6%,Codeforces 3206,复杂任务成功率高 |
| 复杂编码、精准问答、前沿科学推理 | **Claude Opus 4.6 / GPT-5.5** | 和顶级模型还有差距 |
## 总结
DeepSeek V4 在 Agent Coding 和代码理解场景上,明显上了一个台阶。V4-Pro 在 SWE-bench Verified 上拿到了 80.6%,Codeforces 评分 3206 排第一,这个实力对应这个价格,性价比确实到位了。
不过,DeepSeek-V4-Pro 在没有 Coding Plan 的情况下,价格还是偏高。V4-Flash 的定价很香,但在开发场景还无法成为主力。
另外,在复杂的编码、精准问答和前沿科学推理上,跟 Claude Opus 4.6 还有不小距离。不过考虑到 Flash 的价格优势——还要什么自行车?